TimeFlow
Como transformamos o armazenamento de medições do Produto P

Nota do autor
O TimeFlow (conceito, arquitetura e implementação) foi idealizado e desenvolvido por mim. As decisões técnicas, a evolução descrita e as análises apresentadas neste texto são de minha autoria.
O conteúdo foi originalmente produzido no contexto da “Empresa W”, responsável pelo “Produto P”, e é reproduzido neste blog exclusivamente como parte do meu acervo técnico pessoal.
Quando a gente fala em telemetria de energia, a imagem mental costuma ser simples: chega um evento, grava no banco e alguém consulta depois.
No Produto P, isso nunca foi só isso.
Do problema
Até 2024, toda a telemetria de medições de energia da plataforma era armazenada em SQL Server no Azure. Essa escolha vem de um passado distante onde a plataforma ainda estava em seus estágios iniciais de construção e armazenar os dados lá fazia sentido do ponto de vista de tecnologia (da época) e custos.
Claro que, ao longo do tempo, essa estrutura passou a apresentar desafios, mas melhorias contínuas e ajustes finos permitiram que a tecnologia se mantivesse sólida, mesmo em um ambiente já otimizado onde cada nova funcionalidade (envolvendo gestão e visualização inteligente de eventos como cálculos de consumo, indicadores operacionais, consolidações, dashboards, relatórios regulatórios e diversas integrações) exigia revisitar constantemente decisões de infraestrutura e custo.
O problema começou a escalar quando aquilo que parecia uma preocupação distante virou demanda do dia a dia. Novas funcionalidades puxando pesado em armazenamento, visualização e manipulação de dados começaram a chegar, a base não parava de crescer e o nível de processamento exigido subiu junto.
De repente, o banco já estava lidando com tudo ao mesmo tempo: ingestão contínua, alto volume, leitura analítica, agregações por janelas de tempo cada vez maiores, exportações em larga escala… e foi aí que performance e disponibilidade começaram a dar sinais claros de estresse.
Para completar o combo, estávamos cada vez mais perto de ter que subir o tier do banco, com um custo que já não fazia muito sentido para o retorno que aquele modelo ainda conseguia entregar e quando colocamos tudo isso na mesa a conclusão foi inevitável.
O problema não era mais de tuning.
Era arquitetura.
O Produto P precisava de uma atualização tecnológica com foco em três pontos muito claros: performance real para séries temporais, redução de custo estrutural e uma visão de longo prazo que não exigisse redesenhar o modelo a cada nova grandeza ou nova integração.
Caro e gentil leitor, vale abrir um parêntese importante aqui. O problema nunca foi o SQL Server em si. Ele sempre entregou muito bem dentro do que se propunha e sustentou a plataforma por bastante tempo. A questão começa a aparecer quando tudo entra em cena ao mesmo tempo: ingestão contínua, múltiplas fontes de dados, consultas analíticas pesadas e agregações temporais em larga escala. Nesse cenário, o custo arquitetural de sustentar tudo isso em um banco relacional generalista começa a dar sinais claros de cansaço. E, quando aparece, aparece rápido.
Do planejamento
Outro ponto que merece destaque é que na Empresa W, planejamento não é um slide bonito apresentado uma vez por ano e esquecido no fundo do drive. Ele faz parte do funcionamento normal da empresa. Existe uma visão clara da big-picture, dos objetivos estratégicos, dos compromissos assumidos e do ritmo real de execução ao longo do tempo. É isso que permite enxergar onde estamos, para onde estamos indo e, principalmente, o que não faz sentido fazer agora.
No nível de produto, a lógica é a mesma. O Produto P não evolui no improviso. Cada iniciativa passa por um processo estruturado de análise, alinhamento com objetivos maiores e avaliação de impacto técnico e de negócio. Existe uma visão de curto, médio e longo prazo, com prioridades bem definidas e espaço controlado para evolução contínua.
E aqui entra um ponto que costuma ser subestimado: não dá simplesmente para sair fazendo coisa nova, mesmo quando a dor técnica é evidente. Mudanças relevantes exigem tempo, maturação e, muitas vezes, jogo de cintura. É preciso construir e vender uma tese de investimento clara para o produto, mostrando por que aquela iniciativa faz sentido, qual problema resolve, quais riscos carrega e qual retorno se espera, seja em performance, custo, estabilidade ou longevidade da plataforma.
O problema do Storage do Produto P, apesar de já ser evidente para o time técnico, precisava passar pelo caminho certo: ser bem delimitado, projetado, validado com POCs e, só então, aprovado para entrar no ciclo de desenvolvimento (no momento em que fazia sentido técnico, financeiro e estratégico para a plataforma).
E foi em 2025 que esse momento finalmente chegou. Depois de muita preparação, diagramas, POCs, validações e uma coleção respeitável de artefatos, que aqui podem ser simbolizados pelo clássico blueprint do Tom montando a ratoeira para o Jerry, a tese estava madura.
Estimativas feitas, impactos mapeados, riscos conhecidos. O tabuleiro estava montado e, naquele ponto, o arquiteto que vos escreve tinha, enfim, a faca e o queijo na mão para defender e executar com o time as mudanças.
Da arquitetura
e legado
Agora sim, hora de falar de arquitetura. Prometo não começar jogando diagrama na sua cara sem contexto.
Quando ficou claro que o problema era estrutural, também ficou claro que estávamos lidando com um tipo de carga muito específico: séries temporais de verdade. Ingestão contínua, alto volume, agregações por janela, leitura analítica pesada e retenção longa não são um “caso especial” para um banco relacional generalista, é um outro paradigma.
Foi nesse contexto que o PostgreSQL com Timescale se impôs como o núcleo natural dessa evolução. Não como uma troca cosmética de banco, mas como a engine capaz de lidar, de forma nativa, com os padrões reais de acesso e armazenamento que o Produto P já exigia.
A decisão passou por vários fatores, mas dois pesaram bastante: a proximidade semântica com o SQL Server e o alinhamento com a stack que já existia dentro do Produto P. Isso reduzia risco e nos aproximava com uma visão arquitetural que já vinhamos planejando: Postgres.
Mas trocar banco nunca é só trocar banco.
Para falar de arquitetura, precisamos antes entender como as coisas funcionavam até então.
Na época, a cadeia de telemetria do Produto P era relativamente direta:
Front → API Gateway → GraphQL → Storage → SQL Server.
O que chamávamos de Storage é um microserviço responsável por concentrar toda a lógica de acesso a dados de medições.
Ali moravam as regras de negócio, as inserções, as consultas SQL, as agregações, os filtros por período, enfim, tudo que conversava diretamente com o banco.
Funcionava. E funcionou por bastante tempo.
O problema é que esse modelo foi pensado para um outro momento da plataforma e fragilidades começaram a ficar mais evidentes conforme a plataforma crescia.
Uma delas era o acoplamento direto à tecnologia de banco. Uma mudança de engine significaria, na prática, reescrever grande parte do serviço. Mesmo que a lógica de negócio fosse a mesma, o acesso ao dado precisaria ser adaptado em praticamente todos os pontos.
Outra questão era o nível de especialização exigido. Desenvolvedores acabavam criando queries e estruturas que funcionavam no curto prazo, mas que depois precisavam de ajustes finos para lidar com volume, cardinalidade e padrões de acesso típicos de séries temporais.
Não era falta de competência. O modelo não era ideal.
Além disso, métricas de uso, comportamento de carga e gargalos acabavam sendo observados “de fora”, muitas vezes extraídos diretamente do banco, o que não escala bem nem tecnicamente, nem operacionalmente.
Some a isso a dificuldade de pensar em estratégias futuras, como variações de estrutura entre tenants, isolamento mais fino ou até a possibilidade de múltiplos backends de armazenamento convivendo ao longo do tempo.
No fundo, esse outro problema era simples de descrever: o storage sabia demais sobre o banco.
E ao invés de apenas trocar a tecnologia de banco, decidimos dar um passo além e pensar isso de forma produtizável e escalável.
A troca da engine, por si só, não resolveria o problema se fosse feita de maneira direta. Sem um controlador, o Storage continuaria acoplado ao banco e a Produto P apenas trocaria uma dependência rígida por outra.
Foi para evitar esse cenário que o TimeFlow nasceu.
Não como uma camada externa ao banco, mas como o componente responsável por definir, operar e evoluir a forma como uma engine de séries temporais existe dentro do Produto P.
e presente/futuro
O TimeFlow é uma API que, do ponto de vista dos serviços consumidores, se comporta como um banco de dados. Do ponto de vista da plataforma, ele define e governa como a engine de séries temporais é configurada, operada e evoluída internamente.
Responsável por todo o gerenciamento de medições no seu nível mais baixo: persistência, leitura, agregação e organização temporal dos dados.
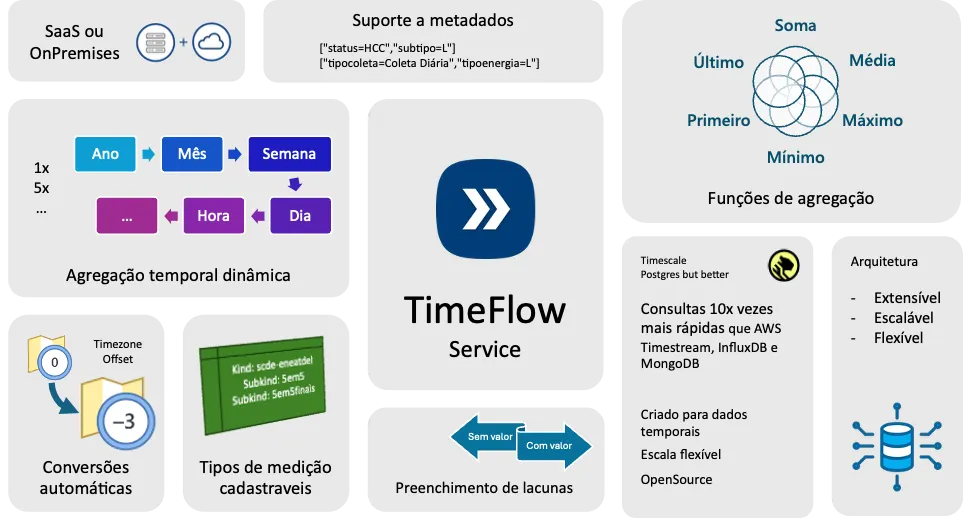
Com suporte a diferentes tipos de medições de forma dinâmica, o TimeFlow centraliza a maneira como o dado é armazenado e acessado, removendo esse conhecimento do restante da plataforma. O contrato passa a ser estável. A implementação, não necessariamente.
Isso não elimina a possibilidade de, no futuro, evoluir ou até trocar a engine subjacente. Mas essa deixa de ser uma preocupação estrutural da plataforma e passa a ser uma decisão interna do TimeFlow, que concentra o conhecimento profundo sobre a operação dessa camada.
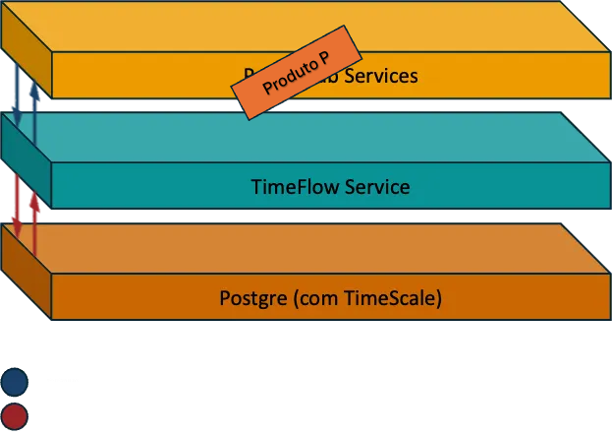
Em outras palavras, a troca de banco deixou de ser um trauma arquitetural e passou a ser uma decisão interna de um produto.
Outro ponto importante a destacar é que o TimeFlow já nasceu considerando uma separação clara entre leitura e escrita no banco de dados. A infraestrutura do StackGres permitiu, de forma bastante robusta, a configuração de instância primária e réplicas, e essa capacidade foi incorporada ao próprio TimeFlow como parte do seu contrato. Na prática, isso deixa de ser “configuração do banco” e vira uma decisão do produto: leitura e escrita passam a ser conceitos de primeira classe dentro do TimeFlow.
Com isso, componentes específicos dentro do Storage passam a saber quando operar em modo de escrita ou de leitura, sempre buscando o melhor desempenho para cada cenário.
Na prática, esse desenho resulta em um comportamento muito mais saudável do banco. As APIs de leitura do Produto P (dashboards, relatórios, consultas analíticas e ferramentas de visualização) em sua grande maioria passam a consultar diretamente as réplicas, enquanto a instância primária permanece focada quase exclusivamente na ingestão de dados e nas operações críticas de escrita.
Além de sustentar as medições já consolidadas da plataforma, sempre existiu um desejo antigo dentro do Produto P: armazenar outros tipos de dados de medição. Um exemplo clássico são os dados raw de integrações como o SCDE, capturados antes de qualquer transformação para o modelo 15 em 15 que a plataforma utiliza.
Por muito tempo, isso foi aquela dor de cotovelo clássica de arquitetura. Não fazia sentido empurrar esse tipo de dado para o banco relacional que já estava no limite, nem tampouco sobrecarregar o serviço de Storage com responsabilidades que ele claramente não deveria assumir. O resultado era simples: a ideia existia, a necessidade era real, mas o desenho não era tão legal assim.
O TimeFlow nasce também para resolver exatamente esse ponto.
De um lado, o serviço de Storage passa a consultar o TimeFlow apenas para as medições padrão do Produto P, já estruturadas e prontas para consumo. De outro, o próprio TimeFlow se torna o repositório natural de outros tipos de medições, incluindo dados raw vindos de integrações externas, que podem ser armazenados e processados no seu tempo.
Esses dados raw deixam de ser um problema e passam a fazer parte do fluxo. Eles vivem no TimeFlow, são transformados quando necessário e só então se convertem em medições no modelo do Produto P, que aí sim seguem para o Storage e para os demais processos da plataforma.
Na prática, o TimeFlow passa a cumprir esse papel duplo: manter o caminho crítico das medições padrão enxuto e previsível, ao mesmo tempo em que abre espaço para experimentação, novas integrações e novos tipos de dados sem comprometer o coração da arquitetura.
Além de desacoplar o Storage da tecnologia de banco, essa camada abriu espaço para algo que antes simplesmente não era viável: controle real sobre onde e como cada tipo de medição é armazenado.
O TimeFlow passou a tratar tipos de medição como entidades independentes, permitindo que, no futuro, uma grandeza específica possa ser direcionada para uma estrutura de storage diferente, sem impacto no contrato exposto para o restante da plataforma. Em outras palavras, não é mais necessário “mudar tudo” para experimentar ou escalar algo em particular.
Essa mesma abstração também foi pensada desde o início com a tenantização em mente. No Produto P, tenants são representados por subscriptions, e o TimeFlow se torna o ponto natural para decisões de roteamento físico do dado. Isso abre espaço para estratégias como isolamento por subscription, distribuição de carga entre diferentes estruturas físicas ou até segmentação por volume e criticidade, tudo sem que o Storage ou as camadas acima precisem conhecer esses detalhes.
O resultado é uma arquitetura que não só resolve o problema atual de séries temporais, mas que cria opções reais de escala no futuro, opções que antes simplesmente não existiam.
e infraestrutura e custos
Antes, estávamos presos a um modelo de SQL Server no Azure, com tiers bem definidos, pouca flexibilidade real e um custo que crescia em blocos grandes, muitas vezes sem entregar de fato uma performance significativa. Escalar significava, na prática, aceitar um pacote fechado e torcer para que ele fosse o mais próximo possível da necessidade real.
Com a nova arquitetura, esse cenário muda completamente. Operando PostgreSQL com StackGres, passamos a ter um modelo enterprise de gerenciamento de banco que privilegia controle e flexibilidade: alta disponibilidade, backup, observabilidade e failover como primeira classe, sem o custo arquitetural do engessamento típico de soluções gerenciadas.
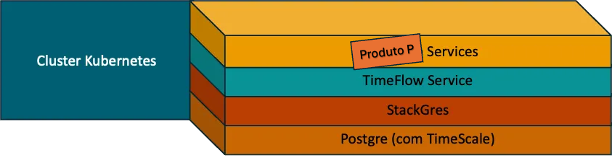
Ganhamos flexibilidade real de escala. Processamento, memória e disco deixam de andar obrigatoriamente juntos. Cada um pode crescer no seu ritmo, de acordo com a necessidade do workload. Isso permite ajustar a infraestrutura de forma muito mais precisa, evitando desperdício e mantendo o custo alinhado ao valor que a plataforma efetivamente entrega.
No fim, não se trata apenas de gastar menos, mas de gastar melhor, com controle, previsibilidade e liberdade arquitetural para evoluir sem ficar refém de um único modelo de escala.
E, no fim das contas, o resultado foi quase irônico: mesmo rodando essa arquitetura dentro de casa, com alta disponibilidade, observabilidade, backup, failover e todo o pacote enterprise habilitado, tivemos uma redução de cerca de 30% no custo total em relação à infraestrutura anterior. A diferença é que, dessa vez, a estrutura não opera no limite. Pelo contrário, ela nos permitiu alguns luxos que antes simplesmente não cabiam no orçamento ou no desenho: instâncias dedicadas de primária e réplicas, folgas reais de processamento, margem confortável de memória e disco (dinamicamente expansível 🔥) para crescer sem tensão.
Enquanto isso, o modelo anterior já havia atingido uma massa crítica clara, onde qualquer crescimento adicional significava custo alto, pouca margem de manobra e decisões cada vez mais defensivas.
Dos resultados
Consultas que antes levavam em torno de 2 segundos em horários de pico passaram a responder na casa dos 200 milissegundos. Em termos práticos, isso significa algo entre 8x e 10x mais rápido justamente nos momentos em que o sistema mais sofria. Mesmo fora dos piores cenários, operações comuns que giravam acima de 300–400 ms caíram para algo próximo de 50–70 ms, uma redução superior a 80% no tempo de resposta.
Mais importante do que a queda absoluta foi o comportamento geral. Antes, a experiência variava bastante ao longo do dia. Pequenas mudanças de carga eram suficientes para degradar leituras, estourar tempos de resposta e gerar aquele efeito cascata que todo mundo que já operou banco sob pressão conhece bem. Depois da mudança, essa variabilidade praticamente desaparece. O sistema passa a responder de forma consistente, previsível e, principalmente, sem surpresas desagradáveis.
Abaixo a imagem que vale mais que 100 palavras.
Antes da nova arquitetura, o sistema até se virava nos horários calmos, mas bastava entrar em carga real para os picos virarem rotina. Em horários de pico, consultas que eram críticas para dashboards e leituras analíticas chegavam na casa de ~2s, e mesmo operações “comuns” frequentemente passavam de 300–400ms. Ou seja: não era só lentidão, era variabilidade. A plataforma ficava refém de contenção e efeitos em cascata que apareciam e sumiam ao longo do dia.
Depois do go-live do TimeFlow (e da stack nova por baixo), o desenho muda completamente. O “pior caso” que antes flertava com segundos passa a operar em ~200ms, o que dá algo entre 8x e 10x mais rápido nos momentos mais críticos (equivalente a ~87% a 90% de redução no tempo de resposta). E no dia a dia, as operações que rodavam em 300–400ms caem para 50–70ms, uma melhora de aproximadamente 5x a 7x (cerca de ~80% a 85% a menos de latência). Não é só mais rápido. É estável.
E esse ganho não veio de “otimização mágica”, veio de desenho. A engine de séries temporais tirou o peso estrutural do workload de time-series do modelo relacional generalista, enquanto a separação clara entre escrita e leitura manteve a primária com folga para ingestão e empurrou o consumo para as réplicas. Na prática: menos contenção cruzada, mais margem operacional e um comportamento muito mais saudável para crescer sem ficar refém de pico.
Dos cravos
Mas claro, nem tudo são flores. E, como costuma acontecer, os problemas de algo complexo são igualmente complexos.
A nova arquitetura resolveu dores estruturais importantes, mas também trouxe uma nova classe de desafios. O primeiro deles é óbvio: complexidade operacional. Antes, muita coisa estava concentrada em um único banco, com um modelo conhecido e amplamente dominado. Agora, existe uma separação clara de responsabilidades, mais componentes envolvidos e decisões que precisam ser pensadas com mais cuidado. Isso exige maturidade técnica, disciplina operacional e um time confortável em operar sistemas distribuídos de verdade.
Outro cravo inevitável é o custo cognitivo. Todas essas tecnologias, infraestruturas e conceitos, separação de leitura e escrita, diferentes tipos de medição convivendo… nada disso é trivial. A arquitetura ficou mais poderosa, mas também mais exigente. Não é o tipo de desenho que se sustenta sem boas práticas, documentação viva e alinhamento constante entre quem desenvolve e quem opera.
Também existe o trade-off clássico entre flexibilidade e simplicidade. Ao ganhar liberdade para decidir onde e como cada dado vive, você assume a responsabilidade de não transformar isso em um caos silencioso. Escolhas que antes eram impostas pela limitação da tecnologia agora são decisões explícitas de arquitetura. Isso é ótimo desde que alguém esteja olhando para o todo e garantindo coerência ao longo do tempo.
Um dos cravos mais chatos que apareceram nessa jornada foi um que, à primeira vista, parecia até “imaginação do time”: pressão de disco no banco… sem nenhum gráfico tradicional gritando por socorro.
Os dashboards de IOPS e bandwidth estavam “ok”. Nada estourando, nada evidente, nada que justificasse os sintomas. Só que o banco estava sentindo. E sentindo de um jeito intermitente e difícil de explicar: momentos de degradação, latência variando e um comportamento que não batia com o que a infraestrutura dizia estar acontecendo.
O vilão aqui tinha nome: WAL.
O write-ahead log é aquele mecanismo do Postgres que garante durabilidade. Tudo que “mexe” no dado gera escrita no WAL, e isso é ótimo… até o dia em que você descobre que está gerando WAL como se fosse confete em carnaval. E o pior: esse tipo de escrita pode ser rápido e constante o bastante para não aparecer claramente nos gráficos “macro” do Azure, que olham para IOPS e bandwidth como se o mundo fosse sempre um fluxo contínuo e previsível.
O que estava acontecendo era o tipo de problema que só aparece quando a vida real bate na porta: algumas integrações externas mandavam milhões de updates repetidos, muitas vezes com os mesmos valores. No mundo ideal, isso seria um “no-op”. Na prática, era update do mesmo jeito. Mesmo sem mudar nada do ponto de vista lógico, o banco precisava registrar a operação, propagar o WAL e… lá se ia PSI de disco. Era um incêndio silencioso: não parecia grave no gráfico, mas queimava por dentro.
A solução foi uma daquelas que dá gosto, porque resolve o problema e ainda prova o valor do desenho: ajustamos o TimeFlow para suportar, como opção, um modo de update “inteligente”, onde a escrita só acontece quando existe mudança real no payload. Se não mudou, não escreve. Se não escreve, não gera WAL desnecessário. Simples, porém cirúrgico.
E aqui vem a parte bonita (e bem pouco glamourosa) da arquitetura: fazer isso no TimeFlow foi um ganho gigante porque concentrou a regra num único lugar. Sem ele, essa otimização teria que existir em cada pedaço do sistema que atualiza medição. E pior: muita gente acabaria implementando do jeito mais caro possível, consultando o dado antes só para descobrir se “mudou ou não” e então decidir se atualiza. Resultado: mais roundtrip, mais carga, mais latência, isso só trocaria um problema por outro.
Nós conseguimos diagnosticar isso por combinações de métricas de requests combinadas com métricas escondidas nos discos dos node + logs do stackgres/pg.
A gente sempre fica com uma pulga atrás da orelha quando cria um ponto único de responsabilidade, porque isso também pode virar um ponto único de falha. Só que existe um trade-off aí: se esse ponto único for o componente mais lapidado, mais observado e mais otimizado da arquitetura, ele vira exatamente o lugar certo para concentrar controle. Em vez de espalhar decisões por vários serviços (cada um com sua versão da verdade), você observa e governa o sistema por um ponto central, consistente e auditável. Menos improviso distribuído, mais previsibilidade.
Da, enfim, conclusão
No fim, vale aquele ditado de sempre: não existe bala de prata. Não existe tecnologia mágica (às vezes até parece que existe, rs) ou banco perfeito. O que existe são decisões bem calculadas, validadas com parcimônia, com o mínimo de hype e com os olhos de Thundera (alerta de idade), daqueles que dão visão além do alcance e te preparam para o que vem pela frente.
No caso do Produto P, a mudança nunca foi sobre seguir tendência ou trocar tecnologia por trocar. Foi sobre escolher onde investir energia ⚡️ e construir uma base que servisse melhor o produto hoje, já pensando nas próximas evoluções, sem empurrar uma refatoração pro amanhã. Algumas concessões foram feitas, alguns cravos sempre aparecem no caminho, mas quando a direção é clara, dá até pra fazer um bom chá com eles.
Porque, no fim das contas, arquitetura não é um fim em si mesma. Ela existe para manter tudo de pé, mesmo quando algumas marteladas nas paredes são necessárias.
Post image: “The Time” from Victoria Dubovyk.